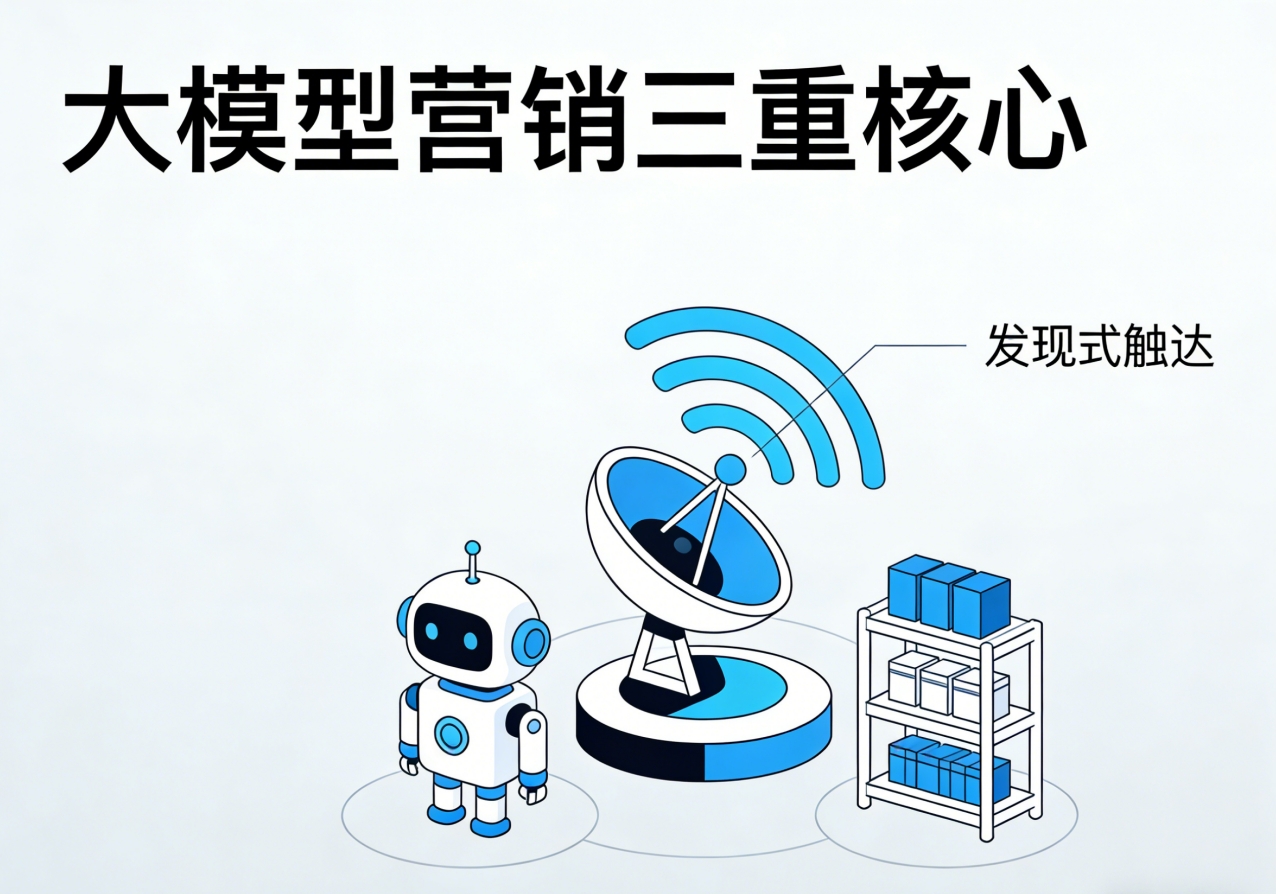
百度热点
百度热点
 抖音热榜
抖音热榜
 新浪微博
新浪微博
 今日头条
今日头条
 腾讯新闻
腾讯新闻
 知乎热搜
知乎热搜
 36氪
36氪
 雪球网
雪球网











Copyright @2024 Bizsoso 粤ICP备14045711号-8